(Day 36) 입출력의 버퍼와 데코레이터 패턴

복습
파일 입출력
파일로 문자열이나 숫자 등의 데이터를 출력하고 읽을 수 있는가?
FileInputStream, FileOutputStream 에 대해서 설명할 수 있는가?
무조건 바이트 배열로 입력하고 출력할 수 있는 스트림이다. 파일 입출력의 시초가 되었던 유닉스의 read()에서 유래했다.
상속 사용법
상속을 이용하여 기존 클래스에 기능을 추가할 수 있는가? DataInputStream, DataOutputStream을 직접 작성해봤다. FIS, FOS 를 상속받아서 말이다.
애초에 왜 파일입출력을 사용하려고 하는가?
메모리에 올라간 인스턴스는 프로세스(메모리에 올라간 프로그램)가 종료되면 제거된다. 만들어둔 데이터들을 저장할 수가 없는 것이다.
파일입출력에서 비트쉬프트의 중요성
- 파일입출력에서 바이트 단위만 지원한다면, 1바이트를 초과하는 타입들은 bit shift operation을 이용해야 한다.
- 저장(입력)할 때는 맨 앞부터 출력하기 위해 8비트 * (타입 크기 - 1) 부터 쉬프트 거리를 8씩 줄여나가면서 출력하면 된다.
- 로드(불러오기) 할 때는 비트쉬프트한 부분들을 OR 연산하는 방법을 쓸 수 있다.
학습
파일입출력시 별도의 경로를 지정하지 않고 파일명만 준다면, 실행되는 경로를 기준으로 파일이 만들어진다. IntelliJ 에서 Gradle 을 통해서 build / run 하고 있다면 build.gradle 설정파일에서 설정된 경로가 기준이 된다.
바이트 배열을 만들어 둔 것에 String생성자 중 source가 되는 바이트배열, 바이트배열을 읽을 시작점(오프셋), 배열에서 읽어들일 개수(Length), 캐릭터셋) 이렇게 객체를 생성하여 String 객체를 만들 수 있다. 그렇게 파일에 저장된 정보를 로드할 수 있다.
버퍼(Buffer) 기능 추가하기
성능차이가 아주 많이 날 수 있다. 기존의 입출력 방식, 그러니까 read(), write() 를 사용하는 경우를 분석해보자. 기존 방식은 왜 비효율이 발생하는 걸까?
read(), write() 를 사용하려면 그 데이터를 읽거나 쓰기 위한 위치를 찾아야 한다. 그러고 나서 데이터를 읽고 쓴다.
| $RequiredTime = DataSeekTime + [read | write]Time$ |
그래서 여러번 read(), write() 메서드를 호출하게 되면, ==호출 회수만큼 Data Seek Time이 증가한다.==
이 Data Seek Time을 줄이기 위해 사용하는 것이 버퍼이다. 예전에 컴퓨터 구조에 대해서 사용되었던 비유인데, 뷔페에서 음식을 먹는 경우다.
한 숟가락, 한 젓가락치를 자리로 가져와서, 먹은 다음에, 다시 음식이 놓인 곳으로 가는 건 너무 귀찮다. 사람들은 자기 접시에 먹을 걸 꽤나 많이 먼저 담아두고 먹는다. 그러면 음식을 받으러 가는 시간을 최소화할 수 있기 때문이다.
데이터도 마찬가지다. 한 숟가락, 한 젓가락치의 데이터만을 가져와서 처리한 다음에 다시 데이터가 있는 곳으로 가는 건 Data Seek Time을 매우 비효율적으로 증가시킨다. 그래서 자기 버퍼에 꽤나 많이 먼저 담아두고 처리한다.
버퍼를 왜 써야 하는지를 짧게 말하면?
입출력시간을 줄이려면 입출력횟수를 줄이는게 중요하다. 버퍼는 입출력횟수를 줄이기 위해 쓴다.
버퍼 기능을 가진 스트림을 직접 작성할 때 주의점 (읽기)
1
2
3
4
5
6
7
8
9
10
11
12
13
@Override
public int read() throws IOException {
if (cursor == size) {
cursor = 0;
size = super.read(buffer);
if (size == -1) {
return -1;
}
}
return buffer[cursor++] & 0x000000ff;
// 주의! int 4바이트에서 끝 1바이트만 남겨야 한다.
// 앞 3바이트가 [맨 끝 바이트의 비트가 1로 시작하는 경우에]
// 그 비트들이 1로 '자동으로'채워지기 때문이다.
리턴 타입이 int 인데 byte 값을 주니까 바이트단위로 자동타입변환이 되는데, 첫 시작이 1비트면 음수로 판단해서 (마찬가지로 2의 보수법을 쓰는 byte 정수의 음수를 말한다.), 좌측에 3바이트가 추가될 때 그 추가되는 바이트의 비트들을 전부 1로 채워버린다. 그거 뺴주려고 0xFF랑 and해주는 것이다.
버퍼의 크기
버퍼의 크기는 보통 8kB 이다. 왜 8 kilo Byte 밖에 안되는가? 그리고 자바에서 왜 버퍼 크기를 크게 잡으면 안된다고 하는가? 요새 16, 32기가바이트의 RAM이 대세인데도?
자바로 만드려는 것이 서버 프로그램이기 때문이다. 메서드를 호출할 때, 버퍼를 위한 배열을 하나 만든다고 하자. 근데 이 메서드는 한번에 하나씩 호출되는 것이 아니라, 적게는 수십에서 많게는 수천만의 클라이언트가 동시에 호출할 수 있다. 그래서 메서드에서 성능을 위해 필드 크기를 무작정 늘릴 수 없는 것이다.
만약 10만번의 동시 호출이 있는 경우, 8kB의 필드 하나를 갖는 메서드는 메모리를 얼마나 차지하게 될까? 단순하게 필드의 크기와 생성해야 하는 수만 곱하더라도, 이렇게 나온다.
8(bit) * 1024(k) * 100_000(clients) = 819_200_000 bit
- 819_200_000 bit
- $= 819,200,000 / 8 / 1024^2MB = 97.65625MB$
메서드에 변수가 하나만 있을까? 8KB 필드 하나만 하더라도 10만건 호출이면 약 98MB의 메모리가 요구되기에, 버퍼와 같은 변수들의 크기에 주의해야 한다.
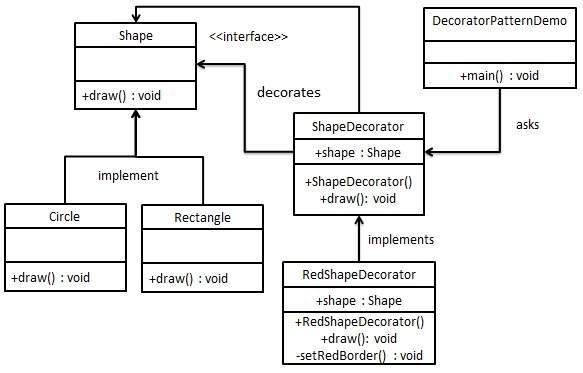
데코레이터 패턴
상속을 이용하여 다양한 기능을 추가시킨 서브클래스들을 만드는 건 코드 중복을 해결하는 좋은 일이다. 그런데 그 좋은 일을 너무 많이 하면(?) 너무나도 많은 서브클래스가 생성되는 문제가 생길 수 있다.
클래스가 많으면있는 클래스들을 찾아보기보다도, “에이 그냥 새로 만들고 말지” 싶을 것이다. 서브클래스들끼리 기능이 중복되는 문제도 생길 것이다.
InputStream이 대표적이다. FileInputStream 클래스를 상속한 DataInputStream, BufferedFileInputStream이 서브클래스로 등장하고, DataInputStream을 상속한 BufferedDataInputStream 서브클래스도 생기고 할 수 있다. 특히, (잘못된 것 아님!!) 다중상속을 허용하지 않는 언어인 java에서 이러한 서브클래스의 대량생산을 해결하기 위한 노하우(디자인패턴)를 GoF가 정리한 것이 있으니, 이것이 데코레이터 패턴이다.
비유
조립식, 모듈식의 제품들이 많다. 핸드폰 배터리는 이제 대부분이 일체형이지만, 예전에는 조립식이었다. 차량이나 컴퓨터 같은 것들은 교체 가능하거나 추가 가능한 부품들을 가지고 옵션을 만들어서 판매한다.
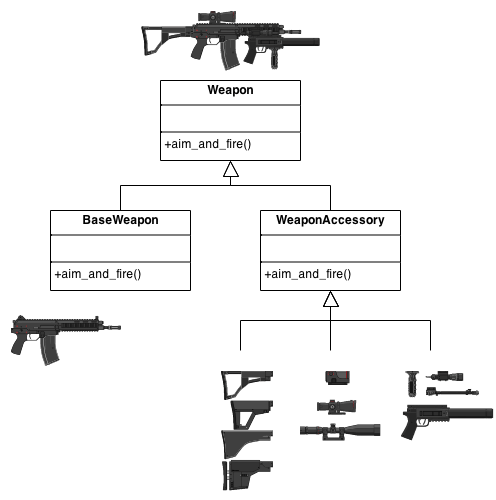
FIleInputStream 도 그렇다.
클래스 다이어그램을 보면, 요렇게 상속을 한 (슈퍼클래스를 확장한) 서브클래스가 사용한다는 표시의 화살표로 슈퍼클래스를 가리키는 클래스 다이어그램을 볼 수 있다.
인기직장에선 뭘 시켜도 잘할 수 있는 인력을 갖고 싶어한다. 뭘 시켜도 잘할 수 있는 걸 어떻게 판단하는가? 기초의 단단함이다. 객체지향. 디자인패턴. 리팩토링, 클린코드… 중심이 단단한 사람. 수학, 논리학, 문제해결에 대한 능력.. 어떻게 해서든지 해야만 할 것이다.
Vue.js, React, Angular 클론코딩 해봤다? 이런 것은 피상적인 것. 프레임워크일 뿐이다.
기본이 단단한, 학습력이 뛰어난 사람이 되어야 한다.
데코레이터 패턴에서 느낀 거
레고같다. 레고 블럭은 모양이 무한하지 않다. 그러면 복잡해질 것이다. 그러나 레고 블럭을 조합해서, 적은 개수의 모양으로 훨씬 많은 모양을 만들 수 있다. 근데 더 정확하게 느껴지는 건, LittleBits라는 모듈식 전자기기다. 이렇게 끼우고 끼우고 끼워서 만는 건 코드의 모양하고도 유사하다. 아규먼트로 끼우면 진짜 모양이 비슷하다.
1
2
3
4
void saveAssignment() {
try (
DataOutputStream out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("assignment.data")))
) {
진짜 너무 비슷하게 생겼다. 이게 없었으면 저 완성된 모양마다 별도로 클래스가 있어야 했을 테니.. 디자인 패턴은 개발자의 스트레스로 발견된 노하우다.
UML - Class diagram
- Inheritance 상속 클래스 선언부에 A extends B 로 드러난다.
- Association 연관 A클래스의 메서드를 사용할 때 지속적으로 사용되는 B 클래스의 객체가 있다. 이 때 B 객체를 의존객체라고 하며, A 클래스가 B 클래스를 사용(연관)한다고 한다.
Aggregation 집합 코드는 Association과 동일하다. A클래스가 B클래스를 집합관계로 가지고 있다고 한다면, 연관과 동일하게 B클래스의 객체 주소를 가지고 있다는 것이다. 반복합니다. 코드는 Association과 Aggregation이 동일하게 구현됩니다! 포함을 위한 것인지 연관을 위한 것인지는 실제 어떻게 사용되는지가 중요한 것입니다. 반복합니다. 코드는 Association과 Aggregation이 동일하게 구현될 수 있습니다! 개발자들은 싸우지 마시기 바랍니다. 교리대로만 살아가려고 하는 교조주의. UML은 의사소통을 위한 것이다! UML은 설계 중 의사소통을 위한 것인데 이것이 연관이냐 집합이냐 싸우려고 하니, 포함(집합)을 뺴자는 이야기도 나왔다. (Robert C. Martin) 실전 UML 인가 하는 책.
Composition이라는 Relation도 있다. 이 관계는 복합연관이라고 번역되는데, A 클래스가 B 클래스를 포함(Aggregation) 하는데, 아주 강하게(?) 포함한다는 의미이다. 이 또한 java에서 사용, 포함과 동일하게 코드로 구현된다. 그런데 A 클래스에서 만들어지고, A클래스에서만 사용되고, A 클래스가 가비지가 되면 같이 가비지가 되어 제거되는 클래스를 A클래스에 Composition relation에 있다고 하는 것이다. 즉 독립적이지 않은 것이다. 마더보드 교체가 불가능한 컴퓨터가 있다고 하면, Aggregation: Computer ◇ㅡ> Mouse Composition: Computer ◆ㅡ> Motherboard 이렇게 둘 연관과 비슷하게 실선에 화살표, 그리고 45도로 돌린 정사각형을 쓴다. 대신 정사각형 내부를 채운다.
- Dependency 라는 relation 도 있다. 이는 의존이라고 번역되는데, 특정 메서드를 사용할 때 꼭 필요로 하는 외부 객체가 있는 경우를 말한다. 이는 점선에 화살표다. A ——-> B
연관,집합,복합연관,의존… 대부분 다 그냥 연관으로 그려진다. 코드의 구현도 다를 것이 없기 때문이다. 그러나 다른 문서를 볼 다를 개발자들에게 ‘반드시’ 알리고 싶은 관계가 있다면 이를 작성한다. UML 관계는 위 5가지 외에도 더 있지만 위 5가지가 제일 중요하다.
코딩의 상황극
상황극을 정확히 다 할 수 있다면 모든 경우의 수에 대해서 상황극을 다 보았다면 버그가 없을 것이다. 아니면 버그가 있을 것이다.
커리어와 시간에 대해서
자바를 2주 4주만에 끝낸다 이런 거는 완전히 BULLSHIT 이다. 해보고 느낀다. 2주~4주 문법 하고 스프링 시작한다, 이런 건 양산형 개발자를 만드는 과정이고 들을 가치가 없는 과정이다. SSAFY는 문법과 같은 기초들을 이미 알고 있거나 독하게 자기가 할 수 있는 사람을 뽑는다. (전공/비전공) 안그러면 강퇴된다. 우테코도 비슷할 듯.