(Day 51) Thread의 재사용(wait(), notify())과 ExecutorService API

Review
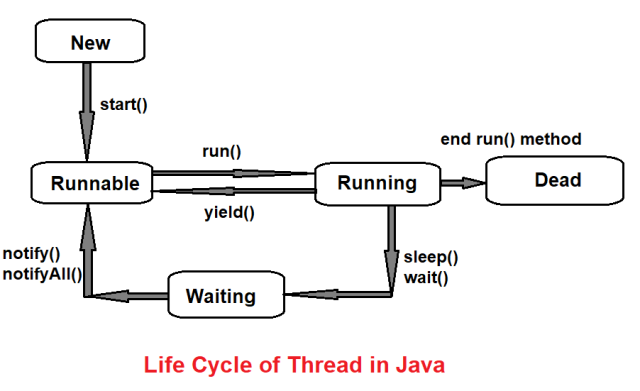
Thread Life Cycle
- start() -> Running (able to use CPU resource)
- sleep() -> Not runnable (reject/unable to use CPU resource)
- When end the call of method -> Dead
- Dead thread can not be started again.
- join() -> Wait for other thread
Priority of Threads
Thread 들도 우선순위를 가질 수 있다. 그러나 실제로 스레드를 관리하는 것은 OS다! (JDK21부터 사용가능한 virtual thread는 JVM이 관리)
CPU Scheduling
- 윈도우: Round-robin
- UNIX/LINUX (Ex. macOS): Prioirty 이라고는 하는데, 실제로 짧은 작업을 테스트해봤을 때는 우선순위를 입력한 것이 유의미한 차이를 보이지 않았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
// 스레드의 생명주기(lifecycle) - 우선 순위 설정
package com.eomcs.concurrent.ex4;
public class Exam0220 {
public static void main(String[] args) throws Exception {
class MyThread extends Thread {
public MyThread(String name) {
super(name);
}
@Override
public void run() {
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000000000; i++)
Math.asin(38.567); // 시간 끌기 용. 왜? 부동소수점 연산은 시간을 많이 소요.
long endTime = System.currentTimeMillis();
System.out.printf("%s = %d\n", getName(), endTime - startTime);
}
}
// main 스레드의 우선 순위를 가장 작은 1로 설정한다.
Thread.currentThread().setPriority(1);
MyThread t1 = new MyThread("홍길동(1)");
t1.setPriority(1);
MyThread t2 = new MyThread("임꺽정(10)");
t2.setPriority(10);
// 유닉스 계열의 OS는 스케줄링에서 우선 순위를 고려하여 CPU를 배분한다.
// 그러나 Windows OS는 우선 순위를 덜 고려하여 CPU를 배분한다.
// 그러다보니 우선 순위를 조정하여 작업을 처리하도록 프로그램을 짜게 되면,
// 유닉스 계열에서 실행할 때는 의도한 대로 동작할지 모르지만,
// 윈도우에서는 의도대로 동작하지 않을 것이다.
// 따라서 프로그램을 짤 때 스레드의 우선 순위를 조정하는 방법에 의존하지 말라!
System.out.printf("main 스레드 우선 순위: %d\n", Thread.currentThread().getPriority());
System.out.printf("%s 스레드 우선 순위: %d\n", t1.getName(), t1.getPriority());
System.out.printf("%s 스레드 우선 순위: %d\n", t2.getName(), t2.getPriority());
// t1 스레드 작업 시작
t1.start();
t2.start();
// main 스레드 작업 시작
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000000000; i++)
Math.asin(38.567); // 부동 소수점 연산을 수행하는 코드를 넣어서 실행 시간을 약간 지연시킨다.
long endTime = System.currentTimeMillis();
System.out.printf("main = %d\n", endTime - startTime);
}
}
OUTPUT (macOS, M1 macbook air)
1
2
3
4
5
6
main 스레드 우선 순위: 1
홍길동(1) 스레드 우선 순위: 1
임꺽정(10) 스레드 우선 순위: 10
main = 1774
임꺽정(10) = 1861
홍길동(1) = 1862
윈도우나 리눅스(인텔 제온 골드)에서도 큰 차이가 나지 않았다. CPU 스케줄링 알고리즘이 수렴진화하나보다.
Thread-unsafe
같은 변수에 여러 스레드가 접근 가능하면, 의도치않게 값을 덮어쓰게 되어버리는 문제가 발생한다. 이러한 경우 thread-unsafe한 코드라고 하고, 그것이 발생하는 부분을 critical-section(region) 이라고 한다.
이를 해결하기 위해서 semaphore 개념이 등장하는데, 한번에 접근가능한 스레드의 수를 제한하는 것이다. semaphore 1, 즉 한번에 한 스레드만 접근 가능한 경우를 Mutex(mutual exclusion)라고 한다.
java에서는 mutex만을 지원하며, 이는 synchronized 키워드로 지원한다. mutex를 구현하면 순차처리와 다를바가 없어지는데, 인스턴스 개념과 덧붙이면 아주 편리한 키워드가 된다.
synchronized 메서드를 사용한다고 할 때, 서로 다른 인스턴스(서로 다른 변수)에 각 스레드가 접근하는 경우는 semaphore 1이 만족되므로 스레드를 대기시킬 필요가 없다. synchronized 메서드라고 해도 여러 스레드가 진입해 그 코드를 사용할 수 있다는 것이다.
synchronized는 스레드가 아니라 인스턴스에 대한 mutex를 지원하는 것이다.
반대로 말하면, 여러 개의 synchronized 메서드들이 있고, 그 메서드들이 하나의 인스턴스를 대상으로 한다면, 각 메서드에 하나씩만 스레드들이 들어와도, 한번에 한 스레드만 실행되도록 대기시킬 것이라는 것이다.
synchronized 메서드들은 같은 인스턴스에 대해 스레드를 mutex로 만들어버리기 때문에, 조회 기능 등 변수에 값을 쓰지 않는 경우에도 적용해버리면 병행처리의 장점을 잃게 된다. 막대한 성능상의 손해를 본다는 것이다. 인스턴스에 값을 쓰는지, 그 값을 쓰는 행동이 critical section에 해당하는지 충분히 검토해보아야 한다.
정리하면
synchronized키워드는 인스턴스를 기준으로 critical section에 mutex를 구현한다.
TIL
Thread & Memory
스레드도 객체다. 근데 실제 스레드는 운영체제가 만들고 관리한다. 그 요청을 운영체제가 처리해주면 그에 대한 정보(주소 등)만을 JVM이 힙메모리에 저장하는 것이다.
공부해볼 글: https://www.geeksforgeeks.org/difference-between-java-threads-and-os-threads/
Virtual Thread
공부할 내용이 아주 많은 글! Java의 미래, Virtual Thread, 김태헌 님
2023 DEC에 나온 글이니 앞으로 JDK 버전 업그레이드와 함께 버추얼 스레드 (가상스레드) 적용사례들이 2024년에 아주 많이 등장할 것으로 보임.
java에서 스레드를 만들면
- JVM은 Thread 인스턴스를 생성한다
- 운영체제가 스레드를 만들고(CPU를 쓰고, 메모리를 할당하고),
- 만든 스레드 정보를 JVM에 넘기고,
- JVM이 Thread 인스턴스에 그 스레드 정보를 저장한다.
- 여기서 OS의 스레드를 Peer 라고 부른다.
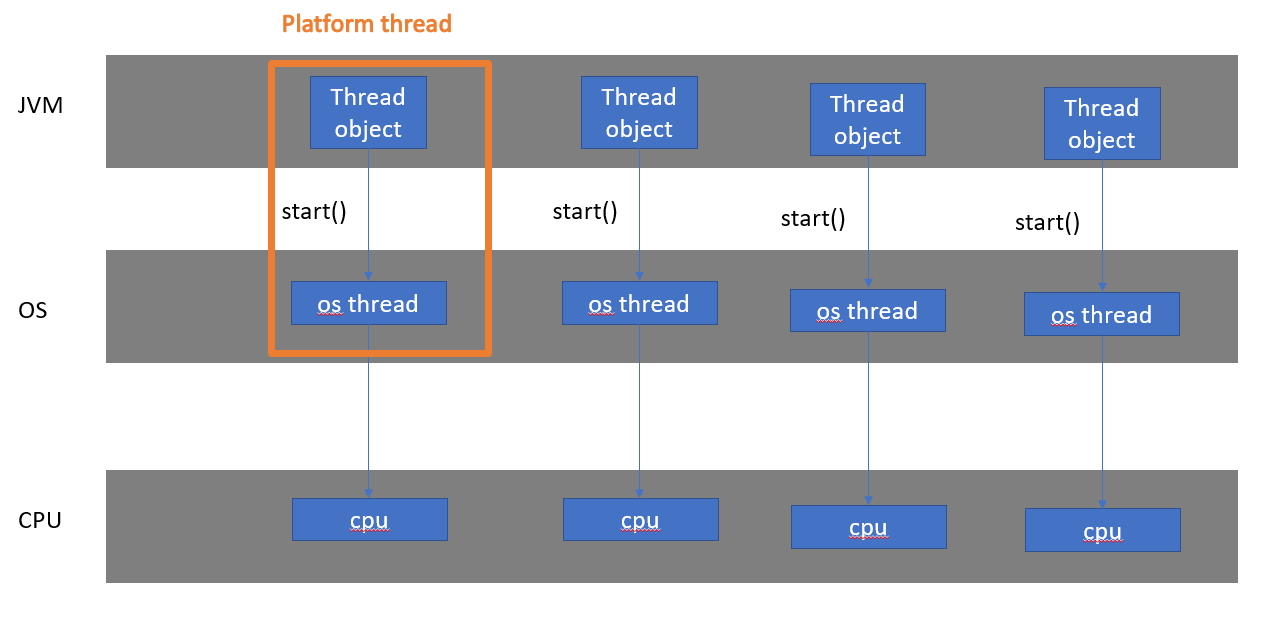
링크에 따르면, Thread는 Stack Size ~2MB, 생성시간에 ~1ms, Context Switching에 ~100µs 정도의 비용이 소모된다고 한다. 스레드를 만드는 것은 비용이 드는 일이다.
그래서 스레드를 Dead 상태로 보내지 않고, 운영체제에서 한번 만들어 둔 것을 계속 쓰는 방법이 대안으로 등장했다.
Thread의 재사용
이전까지 배웠던 Thread Life Cycle을 보고, 스레드를 죽이지(Dead) 않고 계속 사용하려면 어떻게 해야 할 지 생각해보자.
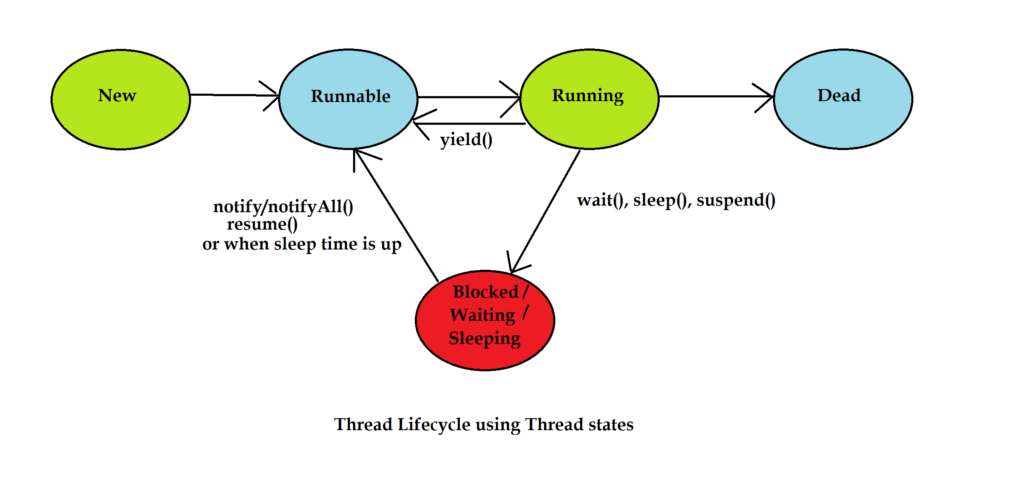
일정시간 sleep 하고 있다가 다시 반복문을 도는 방법이 떠오른다. 이 방법은 마치 정해진 시간마다 오는 기차, 지하철, 버스 같은 느낌이다. 승객이 없으면 출발하지 않게 할 수도 있을 것이다. 그런데 결국 제일 효율적인 방법은 승객이 오기까지 기다렸다가, 오면 출발하는 것이다. java에서도 그런 방식을 위한 메서드들을 Thread API에 만들어뒀다. wait()과 notify()가 그 메서드들이다.
Thread를 재사용하는 방법 => 반복문을 사용한다
- sleep()으로 timeout 걸기
- wait()으로 멈추고, 작업 들어왔을 때 notify()로 깨우기
notify()는 동기화 영역(synchronized area)에서 호출해야 한다.
동기화 영역은 아래를 말한다.
- synchronized로 선언된 메서드
synchronized void m() {}- synchronized로 묶인 블록
synchronized(접근대상) {...}
그렇지 않으면 IllegalMonitorStateException 을 던진다. 왜 synchronized area에서 호출되어야 할까? => TODO
myapp 업그레이드
기존 방식의 문제점
클라이언트가 연결할 때마다 스레드를 생성했고, 연결이 끊기면 스레드가 죽었다.
- Stateless 방식이라서 연결은 요청 할 때마다 일어난다.
- 매번 Garbage가 생성된다!!!
- 매번 Thread를 만드는 데 비용이 들어간다!!!
Thread Pool을 적용해보자
스레드풀, 따로 번역하지 않고 음차한다. 스레드풀은 스레드들의 안식처(?)다. 죽지 않고 살아갈 수 있는 곳이다.
스레드들이 불쌍한 스레드들이 아주 많이 태어나며, 의미없을 만큼 짧은 생만을 살아가는 잘못된 세계를 바꾸고자 스레드풀이 설계되었다.
생명의 탄생에 대해 비관적으로 생각하는 사람이 아닙니다. 단순히 비유만을 위한 것이니 오해하지 말아주세요!!
스레드들은 스레드풀에서 살면서(대기하면서), 누군가 자신을 찾아오면 할 일을 해주고, 그 일이 끝나면 다시 스레드풀로 돌아온다. 스레드풀에서는 누군가가 예외가 발생하여 죽지 않는 이상, 스레드들이 영원히 살아가고, 더 이상 다른 스레드가 태어나지 않는다.
스레드풀이 없을 때는 태어나자마자 부여된 일을 처리하면 죽어서 garbage가 되었다. 스레드풀이 도입되고 나서는 스레드들이 매번 생성될 필요가 없어졌다. 운영체제가 스레드를 할당하기 위해 필요한 시간과 공간도 세이브할 수 있게 되었다.
물론 스레드풀에 있는 스레드들이 항상 영원히 살아가는 것은 아니다. 동적으로 스레드풀 크기를 조절할 필요가 없다면 스레드풀에 스레드 개수를 딱 정해두고 변경할 필요가 없겠지만, 갑자기 스레드가 많이 필요해지는 경우가 생기고, 아닐 때도 생기는 경우라면, 스레드풀의 크기를 동적으로 조절할 필요가 있을 것이다. 그래서 스레드풀이 발전하면, 스레드들이 필요할 때 생성되고, 생성된 스레드들은 재사용되다가, 사용되지 않는 시간이 일정 시간을 넘길 때 (타임아웃을 걸어서) 스레드들을 조건부로 가비지로 삭제하는 기능이 추가된다.
줄여 말하면, ThreadPool에 Pooling 기법이 적용된다. 그리고, 사실 이건 Flyweight Pattern(플라이웨이트 패턴)을 적용한 것이다!
객체의 생성 비용이 큰 경우에, 시간, 공간 생성 ➡️ 보관 🔄 재사용 을 구현하는
순환 참조 끊기
순환참조(쌍방참조, 상호참조)는 OOP에서 유지보수성을 떨어트린다는 것이 명확하게 증명되어있다. 발생한 경우 연결을 끊어줘야 한다.
연결을 끊는 방법은 여러가지가 있을 수 있지만, 대표적으로는 인터페이스를 추가해주는 방법이 있다.
- 제네릭 인터페이스를 만들고
- 사용하는 쪽에서는 해당 인터페이스를 구현하고
- 포함하는 쪽에서는 해당 인터페이스 타입을 사용한다
ThreadPool(스레드풀) 구현하기
ExecutorService와 관련 클래스들이 풍부한 기능으로 지원하고 있으나, 동작 원리를 알기 위해 구현해보자.
직접 구현하기 위해 아래와 같은 생각으로 접근한다.
- 작업을 받아서 처리할
Thread의 서브클래스를 작성한다. (WorkerThread클래스)- 기본적으로 무한반복문을 돈다.
- wait()을 처음 수행해서 notify() 전까지 대기한다.
- try-catch문은 둘 이상을 쓴다. (절대적인 건 아님)
- 작업에 대해서: 스레드 자체는 이상이 없으므로 다시 무한반복문으로 돌아가도록 예외처리해도 된다.
- 그 외에 대해서: 스레드에 이상이 있으므로 무한반복문을 나와서 해당 스레드를 garbage로 만들어야 한다.
- 대기하는
Thread의 서브클래스에게 작업을 전달하며, 없을 경우 스레드를 추가하기 위한Pooling 기법을 구현한 클래스 (ThreadPool클래스)List<WorkerThread>제네릭 타입을 위한ArrayList<>- 스레드를 반환하는
get() - 스레드가 작업을 모두 처리했을 때 리스트로 넣는
revert()- 위에서 언급한 메서드명이 특별한 관례는 아님
- 상호참조를 제거하기 위한 인터페이스
- Pooling, Worker 인터페이스를 작성
- ThreadPool, WorkerThread 클래스 간에 상호참조를 제거하기 위함
구현한 코드는 아래와 같다. Pooling Interface
1
2
3
4
5
6
7
8
package bitcamp.util;
public interface Pooling<E> {
E get();
void revert(E e);
}
Worker Interface
1
2
3
4
5
6
package bitcamp.util;
public interface Worker {
void play();
}
WorkerThread class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
package bitcamp.util;
public class WorkerThread extends Thread {
Pooling<WorkerThread> pool;
Worker worker;
public WorkerThread(ThreadPool pool) {
this.pool = pool;
}
synchronized public void setWorker(Worker worker) {
this.worker = worker;
//스레드가 생성되고 run()이 수행 후 wait()에서 blocking 되어있을 것이라는 보장이 없으므로,
//기다려주거나 Future 클래스를 사용하거나 wait()에 도달하였음을 확인하는게 맞다.
//wait()하지 않은 준비된 스레드에게 notify()하면 무시된다.
//다시 notify()할 일 없다면 영원히 wait() 한다.
this.notify();
}
@Override
public void run() {
try {
while (true) {
synchronized (this) {
this.wait();
//예외발생시 스레드를 더이상 사용불가하므로 catch로 나가서 while문 나감.
}
try {
worker.play();
} catch (Exception e) {
// throw new RuntimeException(e);
e.printStackTrace();
//play()에서 문제가 발생하는 경우는 스레드를 계속 사용할 수 있으므로 다시 while문으로 들어감
}
//작업 다 했으면 pool로 돌아가기
pool.revert(this);
//상호참조(쌍방참조)해버렸다. 나뿐짓이야.. 유지보수에 굉장히 안좋다. 연결을 끊어야 한다.
//연결 끊는 방법? I/F 만들고 그 인터페이스로 연결 끊기
}
} catch (InterruptedException e) {
// throw new RuntimeException(e);
e.printStackTrace();
}
}
}
ThreadPool class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
package bitcamp.util;
import java.util.ArrayList;
import java.util.List;
public class ThreadPool implements Pooling<WorkerThread> {
List<WorkerThread> list = new ArrayList<>();
//워커(스레드) 주세요
@Override
public WorkerThread get() {
if (list.size() > 0) {
System.out.printf("Thread [%s] 꺼내짐", Thread.currentThread().getName());
return list.remove(0);
}
WorkerThread thread = new WorkerThread(this);
thread.start(); //바로 wait() 부터 한다.
return thread;
}
@Override //워커(스레드)가 할일을 다 했으니 돌려보냅니다.
public void revert(WorkerThread thread) {
list.add(thread);
}
}
직접 구현한 ThreadPool 사용하기
아주 간결하게 사용할 수 있다.
1
2
3
4
while (true) {
Socket socket = serverSocket.accept();
threadPool.get().setWorker(() -> service(socket));
}
먼저 윤곽을 보면 다음과 같다.
- 클라이언트가 연결될 때마다 스레드풀에서 스레드를 받고, 람다문법에 따라 Worker 구현체를 파라미터로 받아 setWorker() 메서드를 실행한다.
- setWorker 메서드는 worker 받고, notify()도 수행하므로 만들어지고 wait() 하던 스레드를 실행시킨다.
- 자료구조로 ArrayList를 사용하는데, revert()가 수행될 때 스레드풀에 스레드가 add 되고, get()할 때 remove 된다. 리스트에 없으면 그냥 만들어지고, 나중에 revert()될 때 (작업을 다 수행했을 때) 최초의 스레드가 리스트에 add 된다.
- 이로서 만든 스레드의 재사용이 구현되었다.
조금 더 상세하게 서술하면 아래와 같이 서술할 수 있다.
- threadPool.get() 이 먼저 호출된다.
- 현재 리스트에 들어가있는 스레드가 없으므로, 스레드가 반환된다.
- 그러면 코드는 이렇게 된다.
thread.setWorker(() -> service(socket)); setWorker(Worker worker)는play()메서드만 가진 functional interface인Worker인터페이스의 구현체를 파라미터로 받는다.- 람다 문법이 적용되었다.
play()를service(socket)으로 구현한 구현체가 아규먼트로 들어간다.
- 람다 문법이 적용되었다.
setWorker(Worker worker)는 받은 Worker 객체를 인스턴스 변수에 할당하고this.notify()를 호출한다. 그러므로wait()으로 인한 pending 상태에서 벗어나 worker.play() 메서드가 호출된다.- play() 메서드는 service(socket)을 수행하는 것으로 구현되었다. try-with-resources 문법에 따라 소켓, 데이터 I/O 스트림을 할당하고, 요청에 응답한다. (Reflection API 사용됨)
이렇게 만든 스레드는 삭제할 수 없고, 타임아웃 등의 기능도 없는 차이가 있다. 그래도! 목적인 Pooling 기법이 어떻게 적용되는지 알아보는데 적합하다.
main 스레드에서 준비되기 전에 notify() 하는 경우
notify()가 단 한번만 발생하는 경우, 무시되어 버린다. 다시 notify() 해주기까지 wait() 상태로 영원히 기다린다.
잠든 상태로 만들어 둘 스레드랑, notify()를 하는 스레드가 다른 경우 (보통 부모가 notify) 무시되는 경우가 발생될 수 있다.
start()하여 run()이 실행되고 wait() 이 되기까지 기다려주거나(적은 비용), 생성되었는지를 확인하거나(더 많은 비용) 아니면 최소 스레드들을 미리 만들어두거나 하는 방법들이 해결 방법으로 적용된다.
이러한 내용은 언어나 특정 OS에 종속된 내용이 아니다. 사실상 멀티스레드를 지원하는 모든 OS에 다 적용되는 내용이다.
ExecutorService
java에서 기본 API로 제공해주는 ThreadPool 역할을 해주는 클래스가 있다. 그것이 ExecutorService 클래스이다.
사용방법은 아래와 같다.
- 레퍼런스 변수에 객체를 담을 때, new 생성연산자를 쓰지 않고 메서드로 생성한다. (팩토리 메서드 패턴)
- execute() 메서드는 Runnable 구현체를 파라미터로 받는다. =
execute( ... )메서드롤 호출하면서 아규먼트로Runnable구현체를 넘겨주면 된다. - 스레드가 생성된다.
- start() 메서드가 호출된다.
- Runnable 구현체의 재정의된 run() 메서드가 해당 스레드에서 실행된다.
execute 메서드를 사용하는 것이 꼭 진짜 job을 Worker에게 주는 것 같다.
ExecutorService 만드는 방법
- newFixedThreadPool();
- 고정된 개수의 스레드를 가지는 스레드풀을 만든다.
- newCachedThreadPool();
- 가용 스레드가 없으면 스레드를 만드는 스레드풀을 만든다.
- newSingleThread()
- 1개의 스레드를 갖는 스레드풀을 만든다. 이 외에도 다른 팩토리 메서드들이 지원된다.
SingleThread
단 하나의 스레드만 사용하는 경우… 예약같은 경우는 동시진행을 제한해야 함. node.js는 원치 않아도 싱글스레드 기반. 그래서 요청이 커지면 치명적…